|
Algorithmique pratique et optimisation de code : La génération de labyrinthes |
Le présent document est publié sous la licence « Verbatim Copying » telle que définie par la Free Software Fondation dans le cadre du projet GNU.
Toute copie ou diffusion de ce document dans son intégralité est permise (et même encouragée), quel qu'en soit le support à la seule condition que cette notice, incluant les copyrights, soit préservée.
Copyright (C) 2003, 2004 Yann LANGLAIS, ilay.
La plus récente version en date de ce document est sise à l'url http://ilay.org/yann/articles/maze/.
Toute remarque, suggestion ou correction est bienvenue et peut être adressée à Yann LANGLAIS, ilay.org.
Quand deux petites filles viennent vous voir et vous disent : « Dis papa, dessine-nous des labyrinthes », et
que vous faites de l'informatique l'une de vos passions, voici ce qui arrive : on se met dans
l'idée que c'est aussi simple que de dessiner une boîte en carton et on se retrousse les manches.
Seulement, voilà, après quelques recherches, les choses se compliquent un peu plus que de raison. Le problème est il si complexe, ou bien l'esprit humain le complique-t'il?
Voyons un peu ce que nous pouvons faire...
Commençons par ouvrir le dictionnaire :
Labyrinthe : nom masculin, (du grec laburinthos, palais des haches)
Édifice composé d'un grand nombre de pièces disposées
de telle manière qu'on en trouve que très difficilement
l'issue
Si cette première définition permet très largement une compréhension du concept, elle ne nous est pas d'un grand secours dans l'élaboration d'un programme.
Un labyrinthe est une surface connexe. De telles surfaces peuvent avoir des topologies différentes : simple, ou comportant des anneaux ou îlots.

|

|
| Surface simple connexe | Surface connexe avec îlot |
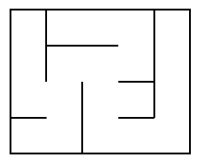
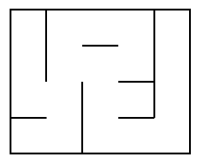
Ces deux surfaces ne sont topologiquement pas équivalentes. Cette différence, rapportée aux labyrinthes, conduit à deux espèces différentes : Le labyrinthe « parfait » et le labyrinthe « imparfait ».
La première espèce correspond à un chemin unique, passant par toutes les pièces. La seconde figure un chemin se recoupant qui peut éventuellement isoler des pièces.
 |
 |
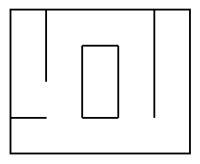 |
| Labyrinthe « parfait » | Labyrinthes « imparfaits » | |
Nous allons nous intéresser aux labyrinthes parfaits.
Les chemins de ces derniers peuvent être représentés par des arbres :
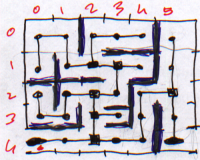 |
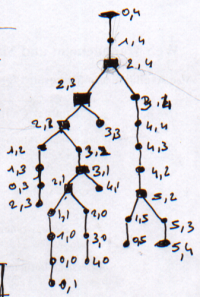 |
| Labyrinthe | Arbre équivalent |
Un labyrinthe rectangulaire parfait de m colonnes par n lignes est un ensemble de m x n cellules reliées les unes aux autres par un chemin unique.
Chaque cellule est reliée à toutes les autres et, ce, de manière unique.
L'équivalence topologique des surfaces connexes simples va nous servir pour affiner notre vision des labyrinthes parfaits :
 |
| Surfaces équivalentes |
Le nombre de murs ouverts pour permettre un chemin unique dans un labyrinthe de mn cellules est identique au nombre de murs ouverts pour un chemin droit de mn cellules, soit mn - 1 portes.
Le nombre total de murs internes possible est :
2mn -
m
- n
Soit 2 murs par cellule (pour ne pas recompter 2 fois les mêmes) en bas et à droite par exemple, moins le nombre de murs limitant le rectangle en bas m et à droite n.
Le nombre de murs fermés dans un labyrinthe parfait est donc :
2mn - m - n - (mn - 1) = (m - 1) (n - 1)
Le labyrinthe est composé de cellules et de murs. Ces deux concepts sont équivalents. Les cellules sont limitées par des murs et les murs limitent les cellules. Il nous faut donc choisir quel concept modéliser.
Étant donné que nous parcourons les pièces, il me parait plus simple, a priori de modéliser les cellules plutôt que les murs.
En première approche on pourrait comparer les ouvertures à des passages et de voir les portes comme des pointeurs vers d'autres cellules. Chaque cellule serait composée de 4 pointeurs. Une porte serait un pointeur vers une cellule voisine, et un mur un pointeur nul.
Cette démarche fonctionne à merveille, mais si l'on regarde de plus près, nous n'en avons pas besoin.
Nous avons besoin de coder l'état des murs Ouvert/Fermé. Il y a 4 portes par cellule, et chaque porte n'a que deux états. Nous n'avons donc besoin que de 4 bits par cellules.
Il nous faudra aussi vraisemblablement savoir si nous sommes déjà passés dans une cellule. Ce qui rajoute 1 bit.
Dans l'absolu, cette façon de représenter les données n'est pas correcte dans la mesure où l'état d'une porte donnée est stocké à 2 endroits (une fois dans les 2 cellules limitées par la porte en question). Pire, une porte n'est vraiment ouverte que si elle est ouverte des 2 cotés. Il faudrait ne stocker les états des portes que dans une seule cellule. Cependant, d'un point de vue pratique, cette redondance ne coûte que 2 bits de trop par cellule, ce qui est d'autant plus négligeable que la taille minimale d'une variable est le caractère. La redondance du code ouvrant les 2 demi-portes est aussi négligeable en temps de calcul.
Le Labyrinthe en lui même est un ensemble de mn cellules. Il nous faut stocker m, n et les cellules elles-mêmes. Il faut de plus tenir compte de l'entrée et de la sortie du labyrinthe.
Le stockage des cellules est un point important. A priori, puisque nous avons affaire à un tableau, on pourrait reprendre un tableau de cellules.
Cependant, on peut y voir 2 inconvénients :
Un tableau bidimensionnel peut être représenté par un vecteur du nombre de cases équivalant, tout en permettant de ne stocker qu'une seule coordonnée. La transcription d'un système de coordonnées à l'autre s'effectue très simplement :
|
x, y -> i : i = my + x i -> x, y : x = i / m et y = i % m * |
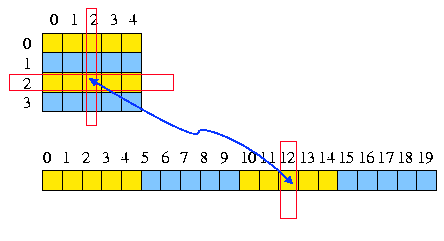 |
* soit, respectivement le résultat de la division entière par m et le reste de la division entière par m ou modulo.
Ainsi, il est possible de s'affranchir des deux inconvénients précédemment cités.
Récapitulons:
Une cellule sera codée sur 1 char.
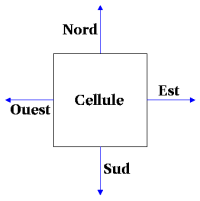
Nommons Nord, Ouest, Sud et Est les quatre portes.
Nord sera le bit 0, Ouest le 1, Sud le 2, et Est le 3.
L'état, visité ou non sera codé sur le bit 4.
Le labyrinthe contiendra 2 entiers m et n, les dimensions du labyrinthe. L'entrée et la sortie, codées indifféremment par leur indice dans le tableau ou par des pointeurs sur les cellules.
Je prendrais dans la suite le pointeurs car leur écriture permet une écriture plus concise qu'avec les vecteurs.
Pour finir, on stockera le tableau de cellule dans un vecteur de caractères.
On obtient la structure de données :
typedef struct _maze_t {
int m, n;
char *in, *out;
char *array;
} maze_t, *pmaze_t;
La première qualité d'un informaticien étant la paresse, car il ne s'agit pas de réinventer la roue, la première chose à faire est d'examiner les algorithmes existants. Rien ne nous empêche de réfléchir à la question par nous-même, mais regarder comment les choses marchent est un gain de temps considérable.
Nous aurions pu commencer par rechercher des solutions dès le départ, avant même s'intéresser à la structuration des données. Mais deux bonnes raisons m'ont imposé une autre approche. D'une part, la structuration des données est un point fondamental et nécessite un analyse sans préjugés si l'on veut obtenir le minimum de redondances. Ce point est indépendant du sujet. C'est l'étape de modélisation. D'autre part, ce sujet précis semble poser pas mal de problèmes aux différents programmeurs qui ont développé des codes de générateurs de labyrinthes en Open Source. Leurs structures de données contiennent en général beaucoup de « superflu ».
Après une recherche sur mon moteur préféré, j'ai relevé deux types d'algorithmes.
Le premier type, utilise une propriété des labyrinthes parfaits précédemment énoncée tel quel : Chaque cellule est reliée à toutes les autres et, ce, de manière unique.
Ce type d'algorithme associe une valeur unique à chaque cellule (leur numéro de séquence, par exemple) et part d'un labyrinthe où toutes les portes sont fermées.
Lorsqu'une porte est ouverte entre deux cellules adjacentes, les deux cellules sont liées entre elles par 2 pointeurs, et l'identifiant de la première est recopié dans la seconde.
Les cellules reliées entre elles forment des listes doublement chaînées. À chaque fois que l'on tente d'ouvrir une porte, on vérifie que les cellules ont des identifiants différents.
Si les identifiants sont identiques, c'est que les deux cellules sont déjà reliées. On ne peut donc pas ouvrir la porte.
Si les identifiants sont différents, la porte est ouverte, et l'identifiant de la première chaîne est affecté à tous les éléments de la seconde chaîne.
Le choix des portes se fait de manière aléatoire.
Voyons la démarche en image:
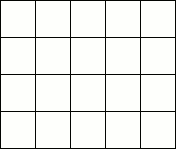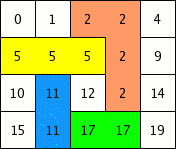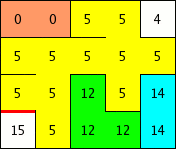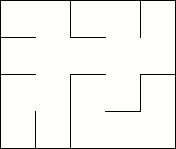
Dans le dernier schéma de la figure précédente, il sera impossible d'ouvrir la porte entre la case anciennement numérotée 7 et la case anciennement numérotée 12.
Il suffit de faire une boucle qui tente d'ouvrir aléatoirement les portes jusqu'à ce que mn - 1 portes soient ouvertes.
Cet algorithme fonctionne très bien, mais nécessite l'implémentation de listes doublement chaînées.
Par ailleurs, la moité de ces listes est parcourue intégralement à chaque ouverture de porte.
De plus, comme le choix des murs à ouvrir est aléatoire, il est nécessaire de gérer la liste des murs disponibles en permanence afin de ne pas « jeter les dès » pour tomber sur un mur déjà ouvert ou un mur qu'on ne peut pas ouvrir. Dans le cas contraire, on risque de prendre un temps infini pour ouvrir toutes les portes. Il est aussi possible de définir un nombre arbitraire de tentatives d'ouverture, et de corriger a posteriori par une autre méthode.
Ces points sont problématiques, tant en terme de complexité que de performances.

|
On part d'un labyrinthe ou toutes les portes sont fermées. Chaque cellule contient une variable booléenne « state » qui indique si la cellule est rattachée au labyrinthe ou non. Toutes les variables sont à faux (0). On choisi une cellule, on met son état à vrai (1). Puis on regarde quels sont les cellules voisines disponibles et dont l'état est à 0 et on stocke la position en cours. S'il y a au mois une possibilité, on en choisi une au hasard, on ouvre la porte et on recommence avec la nouvelle cellule. S'il n'y en pas, on revient à la case précédente et on recommence. Quand on est revenu à la case départ et que qu'il n'y a plus de possibilités, le labyrinthe est terminé. |
L'historique peut être gérée de deux façons:
La formulation récursive donne de très bon résultats pour des labyrinthes de taille modeste. Dès lors que l'on veut générer de grands labyrinthes (1000x1000, par exemple), le programme risque de se terminer brutalement par une erreur de segmentation due à une taille insuffisante de la pile. Dans la mesure où nous n'avons pas de contrôle lors de l'exécution sur la taille maximum de la pile, il est préférable de gérer l'historique manuellement par l'intermédiaire d'un tableau.
Cet algorithme est moins complexe que le premier. Il ne nécessite pas la mise en oeuvre de structures complexes.
Les deux types d'algorithmes ne sont pas tout à fait équivalents d'un point de vue qualitatif.
Le premier type fournit un labyrinthe dont l'arbre est statistiquement mieux équilibré (ou balancé) que celui généré par le second.
En effet, toutes les portes ouvrables ont statistiquement approximativement autant de chances d'être ouvertes.
Le premier algorithme favorisera l'apparition des bifurcations.
A contrario, le second privilégie les chemins. Les arbres seront donc assez fortement déséquilibrés. Plus un chemin est généré tôt, et plus il a de chances d'être long. Plus il est généré tardivement et plus il a de chances d'être court.
Le labyrinthe final sera composé de quelques chemins assez longs avec peu de ramification et les ramifications auront une taille moyenne très inférieure au chemin sur laquelle il se greffe.
Pour des labyrinthes de petites taille, les deux algorithmes donneront des résultats comparables. En revanche, les grands labyrinthes auront des apparences dissemblables.
D'un point de vue quantitatif, le second type d'algorithme sera en moyenne plus rapide que le premier. Une fois encore, sur de petites surfaces, les temps seront comparables. Mais sur de grandes surface, le second se montrera plus performant.
Du point de vue de la de mise en oeuvre, le second algorithme brille par sa simplicité. Il ne requiert pas de traitement lourd et est pleinement déterministe. Il s'impose naturellement comme le meilleur choix possible.
Le code sera réparti en 2 fichers : maze.h (fonctions publiques) et maze.c (implémentation). Le package complet contient aussi une interface X11 (x11.c et x11.h) un fichier principal (main.c) et un Makefile à modifier selon la configuration cible.
Le ficher maze.h ne contient que les prototypes du constructeur, du solveur et du destructeur.
Voyons différentes fonctions de maze.c.
Les directions (Nord, Sud, Ouest et Est) :
/* define directions: */
enum { N, W, S, E };
Les masques binaires qui serviront à isoler les états des portes (eg. la porte Sud a pour état cell & CELL_S) :
/*
* Cell definitions:
* -----------------
* Cells are maped by chars.
* 1st bit maps North door
* 2nd bit maps West door
* 3rd bit maps South door
* 4th bit maps East door
* 5th bit maps visited cells.
*
* bit unset => closed or unvisited
* bit set => open or visited
*/
/* Bit masks: */
#define CELL_N 1
#define CELL_W 2
#define CELL_S 4
#define CELL_E 8
#define CSTATE 16
/* define maze structure */
typedef struct _maze_t {
/* maze size = m lines * n columns */
int m, n;
/* entrence and exit cells */
char *in, *out;
/* array of cells */
char *array;
} maze_t, *pmaze_t;
cell_x, cell_y : Ces deux fonctions donnent les coordonnées d'une cellule à partir de son pointeur.
Ces fonctions procède de la sorte:
cell_at_xy : cette fonction retourne le pointeur sur la cellule aux coordonnées (x, y).
index = m * y + x
on retourne la « index-ième » cellule.
cell_at_dir : cette fonction vérifie s'il y a une cellule à la direction « dir » d'une cellule donnée. Si elle existe, un pointeur sur elle est retourné. Sinon, NULL est retourné.
maze_rand : cette fonction prend un entier n et génère un nombre aléatoire compris 0 et n-1.
maze_rand_border_cell : Cette fonction choisi aléatoirement une cellule sur un des bords.
maze_new : cette fonction pend en paramètres le nombre de colonnes et de lignes du labyrinthe à créer ainsi qu'un pointeur sur une fonction de dessin facultative.
maze_new alloue et initialise le labyrinthe, puis le génère en appelant cell_next.
La fonction de dessin prend 3 entiers correspondant aux coordonnées de la cellule et à la direction de la porte à ouvrir.
maze_destroy : désalloue la structure du labyrinthe.
cell_next : cell_next est l'implémentation de l'algorithme de génération de labyrinthe.
Elle est constituée d'une double boucle infinie. La plus interne fait avancer le chemin le plus avant possible alors que la seconde revient en arrière dans l'historique.
A l'intérieur de la seconde boucle, les cellules jouxtant la cellule courante sont scannées. Une liste des cellules possibles est établie. Ensuite, on choisi de manière aléatoire une des cellules possible. On ouvre les portes entre l'ancienne et la nouvelle cellule. Cette dernière opération est faite de la manière suivante :
cellule |= 1 << i
où i représente la direction (N = 0, W = 1, S = 2, E = 3i)
On prend un caractère à 1, on décalle le 1 de i positions vers la gauche.
Pour la porte N, on a 00000001
pour la porte W : 00000010
Pour la porte S : 00000100
et pour la porte E: 00001000
On applique un « ou inclusif » sur la cellule en cours afin d'ouvrir la porte correspondante.
Pour obtenir la porte équivalente dans la cellule suivante, il suffit l'ajouter 2 modulo 4 à i.
L'ancienne porte est ajouter dans le tableau d'historique et on repart.
http://ilay.org/yann/articles/maze/maze.tgz
Enfin, une applet Flash, fournie par Adrien Béraud, qui illustre les 2 algorithmes de génération :
Et les sources de l'applet.
Le portage de cet algorithme en Javascript par THE MAX
Think Labyrinth: Maze Algorithms http://www.astrolog.org/labyrnth/algrithm.htm
Maze generation algorithm (http://www.worldwidewebfind.com/encyclopedia/en/wikipedia/m/ma/maze_generation_algorithm.html
Xlockmore (http://www.tux.org/~bagleyd/xlockmore.html), module "maze"
Structures de données : Un labyrinthe en C++, Juan Barragan, Login numéro 105, avril 2003
Les labyrinthes, Rémi Peyronnet, http://www.via.ecp.fr/~remi/prog/algo.php3
Générateur de labyrinthe, Romain Vinot, http://www.chez.com/romanino/maze/maze.html
Gestion de la mémoire en C, http://ilay.org/yann/articles/mem/
Structures avancées de gestion de la mémoire (listes doublement chaînées, btrees, hash coding, ...), http://ilay.org/yann/articles/toolbox/
D'autres articles techniques : http://ilay.org/yann/articles/
| Cet article est paru dans LinuxMag France n°62, Juin 2004 | 
|
